-
 Aday Öğrenciler / Prospective Students - CMPE Presentation
Aday Öğrenciler / Prospective Students - CMPE Presentation -
 Alper Alimoğlu successfully defended his PhD thesis
Alper Alimoğlu successfully defended his PhD thesis -
 Emrah Budur Successfully defended his PhD thesis titled Domain-Aware Conversational Open Question Answering for Resource-Constrained Languages
Emrah Budur Successfully defended his PhD thesis titled Domain-Aware Conversational Open Question Answering for Resource-Constrained Languages -
 Assoc. Prof. Dr. Emre Ugur’s project proposal titled “Learning multilevel abstractions for robotic planning” has been accepted by the TUBITAK 1001 program.
Assoc. Prof. Dr. Emre Ugur’s project proposal titled “Learning multilevel abstractions for robotic planning” has been accepted by the TUBITAK 1001 program. -
 Bilgisayar Mühendisliği Bölümü Tanıtımında Araştırma Laboratuvarı Gezildi
Bilgisayar Mühendisliği Bölümü Tanıtımında Araştırma Laboratuvarı Gezildi -
 Berrenur Saylam receives her PhD with her thesis Machine Learning for Well-being Assessment: Exploring Digital Biomarkers
Berrenur Saylam receives her PhD with her thesis Machine Learning for Well-being Assessment: Exploring Digital Biomarkers -
 Our PhD graduate, Dr. Alper Ahmetoğlu, received the BAP PhD Thesis Award
Our PhD graduate, Dr. Alper Ahmetoğlu, received the BAP PhD Thesis Award -
 SIU 2024 Alper Atalay awards
SIU 2024 Alper Atalay awards -
 TURNA Türkçe Dil Modeli yayınlandı
TURNA Türkçe Dil Modeli yayınlandı -
 Alper Ahmetoğlu has successfully defended his PhD thesis
Alper Ahmetoğlu has successfully defended his PhD thesis -
 Yusuf Özben has successfully defended his Master's thesis
Yusuf Özben has successfully defended his Master's thesis -
 Furkan Oruç has successfully defended his Master's thesis
Furkan Oruç has successfully defended his Master's thesis -
 Egemen İşgüder has Presented his MSc Thesis
Egemen İşgüder has Presented his MSc Thesis -
 Emre Girgin tezini başarıyla sundu
Emre Girgin tezini başarıyla sundu -
 Prof. Lale Akarun Bilim Akademisi Asli Üyeliği'ne seçildi
Prof. Lale Akarun Bilim Akademisi Asli Üyeliği'ne seçildi -
 Deniz Dikbıyık received the Best Paper Award at UBMK 23
Deniz Dikbıyık received the Best Paper Award at UBMK 23 -
 CMPE Undergraduate Program's ABET accreditation is renewed!
CMPE Undergraduate Program's ABET accreditation is renewed! -
 Deniz Sezin Ayvaz Has Presented Her MSc Thesis: Investigating Conversion from Mild Cognitive Impairment to Alzheimer’s Disease Using Latent Space Manipulation
Deniz Sezin Ayvaz Has Presented Her MSc Thesis: Investigating Conversion from Mild Cognitive Impairment to Alzheimer’s Disease Using Latent Space Manipulation -
 Gönül Aycı Has Defended Her PhD Thesis: Towards Trustworthy Personal Assistants For Privacy
Gönül Aycı Has Defended Her PhD Thesis: Towards Trustworthy Personal Assistants For Privacy -
 The INVERSE project, in which Assoc. Prof. Dr. Emre Uğur is involved as a partner, has been accepted within the scope of the Horizon Europe program under the CL4-2023-DIGITAL-EMERGING call.
The INVERSE project, in which Assoc. Prof. Dr. Emre Uğur is involved as a partner, has been accepted within the scope of the Horizon Europe program under the CL4-2023-DIGITAL-EMERGING call. -
 Aday öğrenciler için Bilgisayar Mühendisliği bölüm tanıtımı 27 Temmuz 2023
Aday öğrenciler için Bilgisayar Mühendisliği bölüm tanıtımı 27 Temmuz 2023 -
 Assoc Prof Arzucan Özgür receives ERC 2022 Grant for LifeLU: Understanding the Language of Life: Identifying and Characterizing the Language Units in Protein Sequences
Assoc Prof Arzucan Özgür receives ERC 2022 Grant for LifeLU: Understanding the Language of Life: Identifying and Characterizing the Language Units in Protein Sequences -
 Two Awards to CMPE Members at SIU'23 Conference
Two Awards to CMPE Members at SIU'23 Conference -
 Hamed Pirsiavash's Talk on "Learning with limited labels for visual recognition"
Hamed Pirsiavash's Talk on "Learning with limited labels for visual recognition" -
 CMPE 2023 Graduation Ceremony
CMPE 2023 Graduation Ceremony -
 Büşra Tabak has Presented Her MSc Thesis: Automated Assignment and Classification of Software Issues
Büşra Tabak has Presented Her MSc Thesis: Automated Assignment and Classification of Software Issues -
 Spring'23 SENIOR PROJECT AWARDS ANNOUNCED
Spring'23 SENIOR PROJECT AWARDS ANNOUNCED -
 Deniz Dikbıyık presented her MSc Thesis: Driving Behavior Classification Using Smartphone Sensor Data
Deniz Dikbıyık presented her MSc Thesis: Driving Behavior Classification Using Smartphone Sensor Data -
 Batuhan Baykara Defended His PhD Thesis: Abstractive Text Summarization for Morphologically Rich Languages
Batuhan Baykara Defended His PhD Thesis: Abstractive Text Summarization for Morphologically Rich Languages -
 Duygu Serbes Presented her MSc Thesis: Adversarial Robustness and Generalization
Duygu Serbes Presented her MSc Thesis: Adversarial Robustness and Generalization -
 Cem Say's New AI Textbook for High Schools
Cem Say's New AI Textbook for High Schools -
 CMPE is ranked number 1 Computer Science Department in Turkey according to Research.com Rankings
CMPE is ranked number 1 Computer Science Department in Turkey according to Research.com Rankings -
 Melih Barsbey defended his PhD Thesis: Utilizing Nonnegative Tensor Factorization Methods for Inference, Model Selection, and Analysis in Supervised Learning
Melih Barsbey defended his PhD Thesis: Utilizing Nonnegative Tensor Factorization Methods for Inference, Model Selection, and Analysis in Supervised Learning -
 Çağlar Fırat Presented his Ms Thesis: Reinforcement Learning Based Handover Mechanism for Next Generation Mobile Communication Systems
Çağlar Fırat Presented his Ms Thesis: Reinforcement Learning Based Handover Mechanism for Next Generation Mobile Communication Systems -
 İpek Erdoğan Presented her Ms Thesis: Disentangled Representation Learning in Isolated Sign Language Recognition
İpek Erdoğan Presented her Ms Thesis: Disentangled Representation Learning in Isolated Sign Language Recognition -
 Fall'22 Senior Project Awards Announced
Fall'22 Senior Project Awards Announced -
 Dr. Çağatay Yıldız's Talk on "Recent Advances in Black Box Models for Learning Continuous -time Dynamical Systems"
Dr. Çağatay Yıldız's Talk on "Recent Advances in Black Box Models for Learning Continuous -time Dynamical Systems" -
 Prof. Cem Ersoy has been elected as a principal member of the Academy of Sciences
Prof. Cem Ersoy has been elected as a principal member of the Academy of Sciences -
 The Turkish Language Processing Platform (TULAP) by Computer Engineering and Linguistics departments is released
The Turkish Language Processing Platform (TULAP) by Computer Engineering and Linguistics departments is released -
 Emre Bilgili Presented his MS Thesis: A COMMON SUBEXPRESSION ELIMINATION-BASED COMPRESSION METHOD FOR THE CONSTANT MATRIX MULTIPLICATION
Emre Bilgili Presented his MS Thesis: A COMMON SUBEXPRESSION ELIMINATION-BASED COMPRESSION METHOD FOR THE CONSTANT MATRIX MULTIPLICATION -
 Lale Akarun is Elected Vice President of IAPR, International Association of Pattern Recognition
Lale Akarun is Elected Vice President of IAPR, International Association of Pattern Recognition -
 Niaz Chalabianloo defended his PhD Thesis: Stress Measurement and Regulation in Real-Life Using Affective Technologies
Niaz Chalabianloo defended his PhD Thesis: Stress Measurement and Regulation in Real-Life Using Affective Technologies -
 Gökhan Çapan defended his Phd Thesis: Algorithms for learning from online human behavior and human interaction with learning algorithms
Gökhan Çapan defended his Phd Thesis: Algorithms for learning from online human behavior and human interaction with learning algorithms -
 Atıf Emre Yüksel Presented his MS Thesis: Hate Speech Detection in Turkish News Using a Transformer-based Model Enhanced with Linguistic Features
Atıf Emre Yüksel Presented his MS Thesis: Hate Speech Detection in Turkish News Using a Transformer-based Model Enhanced with Linguistic Features -
 Yavuz Köroğlu defended his Phd thesis: Using Machine Learning to Improve Automated Test Generation
Yavuz Köroğlu defended his Phd thesis: Using Machine Learning to Improve Automated Test Generation -
 CoLoRs Research Group at Osaka University for the The Lifelong Robot Learning Project
CoLoRs Research Group at Osaka University for the The Lifelong Robot Learning Project -
 Nanonetworking Research Group Collaboration with Yonsei University, Korea
Nanonetworking Research Group Collaboration with Yonsei University, Korea -
 CMPE 2022 Graduation Ceremony
CMPE 2022 Graduation Ceremony -
 CMPE 2022 Senior Project Poster Sessions
CMPE 2022 Senior Project Poster Sessions -
 Alara Dirik Presented her MS Thesis: 3D Shape Generation and Manipulation
Alara Dirik Presented her MS Thesis: 3D Shape Generation and Manipulation -
 Eren Can Erkaya defended his MSc Thesis: A Comprehensive Analysis of Subword Tokenizers for Morphologically Rich Languages
Eren Can Erkaya defended his MSc Thesis: A Comprehensive Analysis of Subword Tokenizers for Morphologically Rich Languages -
 Esin Gedik has defended her MSc Thesis: Solving Turkish Math Word Problems by Sequence-to-Sequence Encoder-Decoder Models
Esin Gedik has defended her MSc Thesis: Solving Turkish Math Word Problems by Sequence-to-Sequence Encoder-Decoder Models -
 Şaziye Betül Özateş defended her PhD thesis: Deep Learning-based Dependency Parsing for Turkish
Şaziye Betül Özateş defended her PhD thesis: Deep Learning-based Dependency Parsing for Turkish -
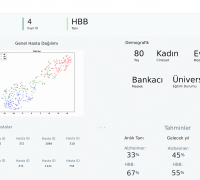 New Project on Alzheimer's Disease Funded by TUBITAK
New Project on Alzheimer's Disease Funded by TUBITAK -
 Bogazici University Virtual Reality Lab (BUViaR Lab) is established
Bogazici University Virtual Reality Lab (BUViaR Lab) is established -
 Boğaziçi University Graduate Programs Promotion Day
Boğaziçi University Graduate Programs Promotion Day -
 Cem Say's popular science book "En Hakiki Mürşit" ("The Truest Guide") is published
Cem Say's popular science book "En Hakiki Mürşit" ("The Truest Guide") is published -
 HUPROG Algorithm Contest
HUPROG Algorithm Contest -
 Özlem Durmaz İncel received the Young Scientist Award from the Science Academy
Özlem Durmaz İncel received the Young Scientist Award from the Science Academy -
 Aykut Bozkurt defended his Ms thesis: SIMD Extensions for Ethereum Virtual Machine
Aykut Bozkurt defended his Ms thesis: SIMD Extensions for Ethereum Virtual Machine -
 Arzucan Özgür received the Excellence in Research Award from Boğaziçi University Foundation (BÜVAK)
Arzucan Özgür received the Excellence in Research Award from Boğaziçi University Foundation (BÜVAK) -
 Lale Akarun received the Excellence in Research Award from Boğaziçi University Foundation (BÜVAK)
Lale Akarun received the Excellence in Research Award from Boğaziçi University Foundation (BÜVAK) -
 Onur Kalınağaç defended his MS Thesis: Prioritization Driven Task Offloading in UAV-Aided Software-Defined Networks
Onur Kalınağaç defended his MS Thesis: Prioritization Driven Task Offloading in UAV-Aided Software-Defined Networks -
 Haluk Alper Karaevli Defended His Ms Thesis: Enhancing Relation Classification by Using Shortest Dependency Paths Between Entities with Pre-trained Language Models
Haluk Alper Karaevli Defended His Ms Thesis: Enhancing Relation Classification by Using Shortest Dependency Paths Between Entities with Pre-trained Language Models -
 Ceyhun Onur Defended His Ms Thesis: ElectAnon: A Blockchain-based, Anonymous, Robust and Scalable Ranked-Choice Voting Protocol
Ceyhun Onur Defended His Ms Thesis: ElectAnon: A Blockchain-based, Anonymous, Robust and Scalable Ranked-Choice Voting Protocol -
 Salih Sevgican Defended his MS Thesis: Network Data Analytics Function in 5G Networks
Salih Sevgican Defended his MS Thesis: Network Data Analytics Function in 5G Networks -
 Efehan Atıcı Defended His MS Thesis: Detection of Free-Standing Conversational Groups with Graph Convolutional Networks
Efehan Atıcı Defended His MS Thesis: Detection of Free-Standing Conversational Groups with Graph Convolutional Networks -
 Berkay Ataman Defended his MS Thesis: An Ontology-based Representation of Semantic Annotations for Relations Extracted from Biomedical Texts
Berkay Ataman Defended his MS Thesis: An Ontology-based Representation of Semantic Annotations for Relations Extracted from Biomedical Texts -
 Gökçehan Kara Defended his PhD Thesis: Parallel Network Flow Algorithms
Gökçehan Kara Defended his PhD Thesis: Parallel Network Flow Algorithms -
 Baran Kılıç Defended His MS Thesis: Parallel Analysis of Blockchain Transaction Graphs
Baran Kılıç Defended His MS Thesis: Parallel Analysis of Blockchain Transaction Graphs -
 CmpE students ranked first in Inzva programming contest
CmpE students ranked first in Inzva programming contest -
 Best Paper at Controllable Generative Modeling in Language and Vision Workshop at NeurIPS
Best Paper at Controllable Generative Modeling in Language and Vision Workshop at NeurIPS -
 CMPE students and faculty run in the 43rd İstanbul Marathon!
CMPE students and faculty run in the 43rd İstanbul Marathon! -
 Dr. Emre Uğur received BAGEP 2021 award
Dr. Emre Uğur received BAGEP 2021 award -
 İhsan Mert Özçelik defended his PhD thesis with the title QUALITY OF EXPERIENCE - DRIVEN DYNAMIC ADAPTIVE STREAMING OVER HTTP
İhsan Mert Özçelik defended his PhD thesis with the title QUALITY OF EXPERIENCE - DRIVEN DYNAMIC ADAPTIVE STREAMING OVER HTTP -
 Three Medals to Boğaziçi Students in International Mathematical Olimpiad 2021
Three Medals to Boğaziçi Students in International Mathematical Olimpiad 2021 -
 Gökcan Çantalı ranked third in the best MS Thesis, IEEE CS Turkey
Gökcan Çantalı ranked third in the best MS Thesis, IEEE CS Turkey -
 Assoc. Prof. Emre Uğur has been awarded the Excellence in Teaching Award by the Faculty of Engineering.
Assoc. Prof. Emre Uğur has been awarded the Excellence in Teaching Award by the Faculty of Engineering. -
 Welcome to 2021 Students
Welcome to 2021 Students -
 2021 CMPE Students' Ranks
2021 CMPE Students' Ranks -
 Ahmet Cihat Baktır Defended his PhD Thesis
Ahmet Cihat Baktır Defended his PhD Thesis -
 Ali Karakoç Defended His MS Thesis
Ali Karakoç Defended His MS Thesis -
 Zeynep Yirmibeşoğlu Defended her MS Thesis
Zeynep Yirmibeşoğlu Defended her MS Thesis -
 Boğaziçi Üniversitesi Bilgisayar Mühendisliği Tanıtımları
Boğaziçi Üniversitesi Bilgisayar Mühendisliği Tanıtımları -
 Esra Önal Defended her MA Thesis
Esra Önal Defended her MA Thesis -
 Gökçe Uludoğan Defended her MS Thesis
Gökçe Uludoğan Defended her MS Thesis -
 Abdullatif Köksal Defended his MS Thesis
Abdullatif Köksal Defended his MS Thesis -
 Mert Basmacı Defended his MS Thesis
Mert Basmacı Defended his MS Thesis -
 Hilal Dönmez Defended her MS Thesis
Hilal Dönmez Defended her MS Thesis -
 Senior Project Awards Announced
Senior Project Awards Announced -
 Ahmet Beka Ozkan defended his MS thesis
Ahmet Beka Ozkan defended his MS thesis -
 Bronze medal in Southeastern Europe Regional Contest (SEERC)
Bronze medal in Southeastern Europe Regional Contest (SEERC) -
 Serhan Daniş successfully defended his PhD Thesis
Serhan Daniş successfully defended his PhD Thesis -
 H. Birkan Yılmaz Receives BAP-SUP Grant with CONNECT Project
H. Birkan Yılmaz Receives BAP-SUP Grant with CONNECT Project -
 Onur Güngör defended his PhD Thesis
Onur Güngör defended his PhD Thesis -
 Sinem Kafiloğlu Defended Her Doctoral Thesis
Sinem Kafiloğlu Defended Her Doctoral Thesis -
 Digital Transformation - An interview with Lale Akarun
Digital Transformation - An interview with Lale Akarun -
 A Meaningful Gift From Our Students
A Meaningful Gift From Our Students -
 Our Graduate Nadin Kökciyan will be Featured as New Faculty
Our Graduate Nadin Kökciyan will be Featured as New Faculty -
 Lale Akarun Elected Vice President of International Association of Pattern Recognition
Lale Akarun Elected Vice President of International Association of Pattern Recognition -
 Success at Online Programming Contest
Success at Online Programming Contest -
 First Place at IEEE TR Student Branches Algorithm Competition
First Place at IEEE TR Student Branches Algorithm Competition -
 Cognitive Robots that Imagine Other’s Dreams and Make Them Come True
Cognitive Robots that Imagine Other’s Dreams and Make Them Come True -
 Emre Uğur receives TUBITAK 1001 grant
Emre Uğur receives TUBITAK 1001 grant -
 Locating Aircraft Wrecks via Molecular Signals
Locating Aircraft Wrecks via Molecular Signals -
 Boğaziçi University Leader in Artificial Intelligence, Big Data and Robotics
Boğaziçi University Leader in Artificial Intelligence, Big Data and Robotics -
 Collaboration between TUBITAK TUSSIDE and Industry 4.0 Platform
Collaboration between TUBITAK TUSSIDE and Industry 4.0 Platform -
 Boğaziçi University is ranked #1 among the Best Global Universities in Turkey
Boğaziçi University is ranked #1 among the Best Global Universities in Turkey -
 Boğaziçi graduates founded an autonomous vehicle company in the USA
Boğaziçi graduates founded an autonomous vehicle company in the USA -
 Hakime Öztürk Receives the BAP Dissertation Award
Hakime Öztürk Receives the BAP Dissertation Award -
 2020 Publicity Events for Prospective Students
2020 Publicity Events for Prospective Students -
 "de/da" Spelling Corrector
"de/da" Spelling Corrector -
 D3A: Digital Transformation Index for SMEs
D3A: Digital Transformation Index for SMEs -
 Private Industrial 5G Networks
Private Industrial 5G Networks -
 Wearable Wonders
Wearable Wonders -
 New World, New Net
New World, New Net -
 Improving Robustness of Machine Learning Systems
Improving Robustness of Machine Learning Systems -
 Stress detection app for smartwatches, from Boğaziçi University
Stress detection app for smartwatches, from Boğaziçi University -
 Can artificial intelligence and data science save humanity from this crisis?
Can artificial intelligence and data science save humanity from this crisis? -
 Boğaziçi University is the top Turkish university in computer science and electronics
Boğaziçi University is the top Turkish university in computer science and electronics -
 Open Day for Graduate Programs
Open Day for Graduate Programs -
 Pulse as a solution to forgotten passwords
Pulse as a solution to forgotten passwords -
 Prof. Dr. Tuna Tuğcu: Remote education enables learning 7/24
Prof. Dr. Tuna Tuğcu: Remote education enables learning 7/24 -
 Arzucan Özgür Wins the TÜBA-GEBİP Award
Arzucan Özgür Wins the TÜBA-GEBİP Award -
 EU sponsored H2020 project Infinitech started
EU sponsored H2020 project Infinitech started -
 Papers accepted to 14th International Conference on Language and Automata Theory and Applications
Papers accepted to 14th International Conference on Language and Automata Theory and Applications -
 SPECOM'19 Conference kicks off on August 21st at 9:00, with Hynek Hermansky's keynote
SPECOM'19 Conference kicks off on August 21st at 9:00, with Hynek Hermansky's keynote -
 [TR] Bilgisayar Mühendisliği Bölüm Tanıtım Sunumu
[TR] Bilgisayar Mühendisliği Bölüm Tanıtım Sunumu -
 Student with the highest score in TYT goes to the Department of Computer Engineering
Student with the highest score in TYT goes to the Department of Computer Engineering -
 All proposals to TUBITAK 2232 received funding
All proposals to TUBITAK 2232 received funding -
 Best Poster Award at TORK 2019
Best Poster Award at TORK 2019 -
 Spring 2019 Projects Poster Session
Spring 2019 Projects Poster Session -
 Fourth Embedded Car Race
Fourth Embedded Car Race -
 Data for Refugees Challenge Workshop and Award Ceremony
Data for Refugees Challenge Workshop and Award Ceremony -
 Fall 2018 Senior Projects Poster Session
Fall 2018 Senior Projects Poster Session -
 Teams Returning from the ACM SouthEastern European Regional Contest with Success
Teams Returning from the ACM SouthEastern European Regional Contest with Success -
 Second prize in the PARSEME Shared Task 2018
Second prize in the PARSEME Shared Task 2018 -
 AffecTech Training Event
AffecTech Training Event -
 CMPE and EE Departments are hosting SPECOM and ICR
CMPE and EE Departments are hosting SPECOM and ICR -
 Machine Learning İsmail Arı Summer School in Bosphorus
Machine Learning İsmail Arı Summer School in Bosphorus -
 CmpE Graduates of 2018
CmpE Graduates of 2018 -
 RoboAKUT won the third prize in the RoboCup 2018
RoboAKUT won the third prize in the RoboCup 2018 -
 Award Winning Senior Projects
Award Winning Senior Projects -
 Senior Projects Poster Session
Senior Projects Poster Session -
 TORK 2018 Turkey Robotics Conference
TORK 2018 Turkey Robotics Conference -
 The 5th TETAM Interdisciplinary Workshop
The 5th TETAM Interdisciplinary Workshop -
 [TR] Aday Öğrenciler İçin
[TR] Aday Öğrenciler İçin -
 Boğaziçi Techsummit is taking place from 23rd to 25th of February
Boğaziçi Techsummit is taking place from 23rd to 25th of February -
 World University Rankings 2018 by Subject: Computer Science
World University Rankings 2018 by Subject: Computer Science -
 Is Artificial Intelligence Our Master or Slave?
Is Artificial Intelligence Our Master or Slave? -
 Final Project Demos of CMPE 434: Introduction to Robotic
Final Project Demos of CMPE 434: Introduction to Robotic -
 Data for Refugees
Data for Refugees -
 Senior Projects Poster Session
Senior Projects Poster Session -
 New Horizon2020 Project AffecTech: Personal Technologies for Affective Health
New Horizon2020 Project AffecTech: Personal Technologies for Affective Health -
 6. Django Girls-İstanbul etkinliği gerçekleştirildi
6. Django Girls-İstanbul etkinliği gerçekleştirildi -
 Boğaziçi Üniversitesi Endüstri 4.0 Platformu Danışma Kurulu oluşturuldu
Boğaziçi Üniversitesi Endüstri 4.0 Platformu Danışma Kurulu oluşturuldu -
 Random Variable takımı ACM ICPC'de Ukrayna üçüncüsü oldu
Random Variable takımı ACM ICPC'de Ukrayna üçüncüsü oldu -
 RoboAKUT won the 3rd Place in RoboCup 2017 Rescue Simulation League
RoboAKUT won the 3rd Place in RoboCup 2017 Rescue Simulation League -
 A team of researchers won the IJCNN/CVPR ChaLearn Job Candidate Screening Competition.
A team of researchers won the IJCNN/CVPR ChaLearn Job Candidate Screening Competition. -
 Our graduate Dr. Kübra Kalkan won BAP PhD Thesis Award
Our graduate Dr. Kübra Kalkan won BAP PhD Thesis Award -
 First place in Taboo City Guessing AI Challenge to Abdullatif Köksal
First place in Taboo City Guessing AI Challenge to Abdullatif Köksal -
 Bilgisayar Mühendisliği Bölüm Tanıtım Sunumu (2016)
Bilgisayar Mühendisliği Bölüm Tanıtım Sunumu (2016) -
 Successful Woman Entrepreneur of the Year Award to Prof. Pınar Yolum
Successful Woman Entrepreneur of the Year Award to Prof. Pınar Yolum -
 Students won TUSIAD "Bu Gençlikte İş Var 2017" Competition
Students won TUSIAD "Bu Gençlikte İş Var 2017" Competition -
 CMPE Senior Projects Poster Session
CMPE Senior Projects Poster Session -
 RoboAKUT won the first place in the RoboCup Iran Open 2017
RoboAKUT won the first place in the RoboCup Iran Open 2017 -
 Come Together - Computer Engineering
Come Together - Computer Engineering -
 Dr. Albert Ali Salah receives 2017 BAGEP Award
Dr. Albert Ali Salah receives 2017 BAGEP Award -
 EU Funding for Full-time Msc/Phd Positions in Cognitive Robotics and Robot Learning
EU Funding for Full-time Msc/Phd Positions in Cognitive Robotics and Robot Learning -
 Special 6-week training course organized with Havelsan: "Introduction to Machine Learning and Data Analysis"
Special 6-week training course organized with Havelsan: "Introduction to Machine Learning and Data Analysis" -
 Graduate Programs Information Day (April 1, 2017)
Graduate Programs Information Day (April 1, 2017) -
 New Courses Offered This Semester
New Courses Offered This Semester -
 ChaLearn 1st place award in First Impressions
ChaLearn 1st place award in First Impressions -
 New book by Ethem Alpaydın: Machine Learning
New book by Ethem Alpaydın: Machine Learning -
 EU Funding for Full-Time PhD Positions available
EU Funding for Full-Time PhD Positions available -
 UCAml'16 Best Paper Award
UCAml'16 Best Paper Award -
 Okan Aşık won the best paper award at TORK 2016
Okan Aşık won the best paper award at TORK 2016 -
 CmpE 150 Exemption Exams
CmpE 150 Exemption Exams -
 ADAX Project got ITEA3 Award
ADAX Project got ITEA3 Award - Görker Alp Malazgirt is a finalist in Xilinx Open Hardware Design Contest 2016
-
 Etem Deniz has received the 2016 BAP PhD award
Etem Deniz has received the 2016 BAP PhD award -
 Assist. Prof. Arzucan Özgür got the BAGEP 2016 Prize
Assist. Prof. Arzucan Özgür got the BAGEP 2016 Prize -
 "Open Lecture" Drew Large Crowd
"Open Lecture" Drew Large Crowd -
 Monitoring Parkinson Patients at Home (Content In Turkish)
Monitoring Parkinson Patients at Home (Content In Turkish) -
 "Open Lectures" from Boğaziçi University
"Open Lectures" from Boğaziçi University -
 Graduate programs Information Day (April 2, 2016)
Graduate programs Information Day (April 2, 2016) -
 Computer Engineering?
Computer Engineering? -
 CmpE students qualify in Google's HashCode challenge
CmpE students qualify in Google's HashCode challenge -
 Get to know us
Get to know us -
 Senior Projects
Senior Projects -
 "Abbas Güçlü" team wins first slot car race
"Abbas Güçlü" team wins first slot car race -
 Follow us
Follow us -
 A novel app developed by CMPE students
A novel app developed by CMPE students -
 Software Engineering Projects
Software Engineering Projects -
 PhD Defense Day: 3 in 1...
PhD Defense Day: 3 in 1... -
 CmpE Team's success in ACM RecSys Challenge
CmpE Team's success in ACM RecSys Challenge -
 CmpE Team wins award at the EmotiW Challenge
CmpE Team wins award at the EmotiW Challenge -
 BUVAK Award for Excellence in Research
BUVAK Award for Excellence in Research -
 International Evening at CMPE
International Evening at CMPE -
 ComParE 2015 Award to Heysem Kaya
ComParE 2015 Award to Heysem Kaya -
 The H2020 Project "ShakerMaker"
The H2020 Project "ShakerMaker" -
 Cerberus competes for CMPE in RoboCup 2015 World Championship
Cerberus competes for CMPE in RoboCup 2015 World Championship -
 Patent Success from CMPE
Patent Success from CMPE -
 Binnur Görer awarded Anita Borg scholarship
Binnur Görer awarded Anita Borg scholarship -
 CMPE Senior Project Poster Session
CMPE Senior Project Poster Session -
 Our PhD graduate Hande Alemdar wins the BAP doctoral thesis award
Our PhD graduate Hande Alemdar wins the BAP doctoral thesis award -
 Ada Lovelace Day
Ada Lovelace Day -
 2015 Senior Projects
2015 Senior Projects -
 Stanford-Bogazici Introduction to Computing Summer School
Stanford-Bogazici Introduction to Computing Summer School -
 İsmail Arı Computer Science and Engineering Summer School (In Turkish)
İsmail Arı Computer Science and Engineering Summer School (In Turkish) -
 ACM Algorithm Camp
ACM Algorithm Camp -
 Evin Pınar Örnek Awarded Scholarship Grant for Grace Hopper Celebration
Evin Pınar Örnek Awarded Scholarship Grant for Grace Hopper Celebration -
 Robogoal 2014
Robogoal 2014 -
 2014 Senior Projects
2014 Senior Projects -
 Overcoming disabilities through technology - Sign Language Research At CMPE (Content in Turkish)
Overcoming disabilities through technology - Sign Language Research At CMPE (Content in Turkish) -
 ACM International Conference on Multimodal Interaction (ICMI 2014) was hosted by Bogazici University
ACM International Conference on Multimodal Interaction (ICMI 2014) was hosted by Bogazici University - Application to Graduate Programs in Computer Engineering
-
 Introduction to Machine Learning, third edition
Introduction to Machine Learning, third edition -
 BU/CmpE team wins the Physical Load Sub-Challenge Award at INTERSPEECH Computational Paralinguistics Challenge
BU/CmpE team wins the Physical Load Sub-Challenge Award at INTERSPEECH Computational Paralinguistics Challenge - Gül Varol's success in Thumos 2014 Challenge at ECCV
- CmpE website is updated
-
 AAMAS 2015
AAMAS 2015 -
 About Us
About Us - Our PhD graduate Gürkan Gür wins the BAP doctoral thesis award at graduation
-
 15 PhD graduates from Computer Engineering
15 PhD graduates from Computer Engineering


Contact us
Department of Computer Engineering, Boğaziçi University,
34342 Bebek, Istanbul, Turkey
- Phone: +90 212 359 45 23/24
- Fax: +90 212 2872461
Connect with us
We're on Social Networks. Follow us & get in touch.